Technik und Systemarchitektur der "WISSENsAllmende Jena"
Sehr grob gesprochen, benötigt eine Datenplattform drei Dinge: ein Verzeichnis der vorhandenen Daten (Metadaten), die Daten selbst und die Zugriffsmöglichkeiten darauf. In unserer Plattform spielen weiterhin Datenmodelle und ein Identitätsmanagement zur Steuerung von Nutzerrechten eine große Rolle.
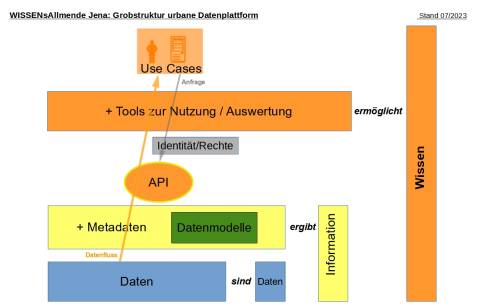
Volltextalternative zur Grafik
Bei der Betrachtung der Grobstruktur gibt es drei Ebenen (auch Layer genannt). In der ersten Ebenen sind die Daten an sich. Bei Anreicherung der Daten durch Metadaten (strukturierte Daten, die Informationen über Merkmale anderer Daten enthalten) bekommt man in der zweiten Ebene die Möglichkeit Informationen zu erhalten. Wenn man diese Metadaten über Schnittstellen sowie Auswertungen veröffentlicht, wird Wissen in der dritten Ebene generiert. Für jeden Anwendungsfall (Use Case) müssen die Daten identifiziert und Metadaten hinzugefügt werden. Durch Auswertungswerkzeuge, wie zum Beispiel Tabellen und Karten, kann man aus den Anwendungsfall spezifisches Wissen erlangen.
Als Verzeichnis (Registry) verwendet die WISSENsAllmende Jena (WAJ) die Lösung PIVEAU von Fraunhofer FOKUS als Datenmanagement-Plattform für den öffentlichen Sektor. Es kann für den flexiblen Aufbau von leistungsstarken, offenen Datenportalen oder internen Datenmanagementsystemen eingesetzt werden. Entscheidend dabei ist die konsequente Anwendung von DCAT-AP, einem Metadatenstandard für den Autausch offener Verwaltungsdaten. Das ermöglicht uns den Aufbau einer universellen, zukunftssicheren Plattform und die Möglichkeit, auch neu hinzukommende Datenquellen und Anwendungsfälle einzubinden.
Ein weiterer wichtiger Aspekt der Metadaten-Ebene ist der modellorientierte Ansatz, den wir im Rahmen der WISSENsAllmende Jena verfolgen. Für alle einzubindenden Daten werden Modelle im Rahmen des Eclipse Modeling Framework (EMF) erstellt und über einen Modellserver zur Verfügung gestellt. Das ermöglicht nicht nur ein effizientes Management von Schnittstellen (API´s), sondern beispielsweise auch von Datenschutz-Aspekten.
Die Daten einer Stadtverwaltung und der städtischen Unternehmen sind sehr vielfältig und heterogen. Wir teilen sie in vier Arten ein, nach denen auch die Datenmodelle und das technische Datenmanagement ausgerichtet werden: Echtzeit- und Sensordaten (eventbezogene Daten), Gegenstände und öffentlicher Raum (Asset- und Geodaten), Controlling – und Statistikdaten (Datenwürfel) sowie Dokumente (Dateien). Strukturell lässt sich damit die gesamte Breite der plattformrelevanten Daten abbilden.
Dabei kann eine Datenplattform nicht unmittelbar mit den Originaldaten arbeiten, da dies Datenschutz-, Performance- und Sicherheitsrisiken bergen würde. Durch Adapter und ETL-Prozesse werden die Daten geladen, entsprechend der Datenmodelle transformiert und beispielsweise durch einen Eventbroker oder in OLAP-Cubes gespeichert. Darauf kann dann mit Hilfe der oben genannten Metadaten zugegriffen werden.
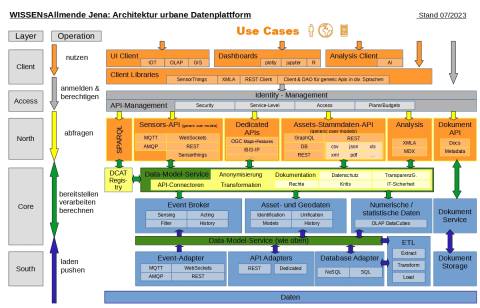
Dies ermöglicht den Zugriff und die Nutzung der Daten durch fremde oder eigene Tools. Dafür stellen wir eine Vielzahl an standardkonformen API´s zur Verfügung, was ebenfalls auf Datenmodellen beruht. Weiterhin wird ein Identitätsmanagement als Basis für schreibende oder aus sonstigen Gründen beschränkte Zugriffe benötigt, das derzeit konzipiert und aufgebaut wird.
Und schließlich stellen wir Clients für Auswertungen zur Verfügung, die die API´s nutzen können. Zur Zeit sind das GIS-basierte Tools für Sensoren und Assets, sowie ein OLAP-Client auf XMLA-Basis zur Auswertung zur Auswertung von Data Cubes.
Gern stellen wir Ihnen weitere Informationen und Dokumentationen zur Verfügung. Alle Softwarekomponenten stehen unter Open Source-Lizenzen; dies entspricht unseren Überzeugungen und ist auch Förderbedingung der Modellprojekte Smart City. Sie sind bzw. werden auf OpenCode.de, der gemeinsamen Plattform der Öffentlichen Verwaltung für den Austausch von Open Source Software, zur Verfügung gestellt.
Hier finden Sie die im Text verwendeten Bilder als PDF-Dokument: